Injecting Code using Imported Functions into Native PE Files
Patching PE files is easy. Injecting new code that uses functions from external modules, however, is more complicated. In this post, we are implementing a method for rebuilding import directories, such that we can inject any type of code in an arbitrary PE file.
The Problem
Let’s say you have a Portable Executable (PE) file, and you want to modify it.
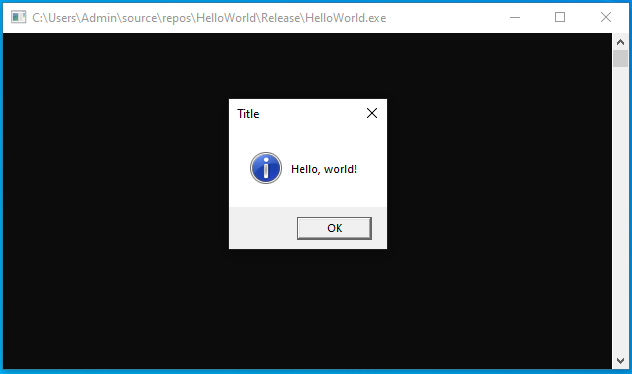 A boring application we want to modify
A boring application we want to modify
Maybe you want to add some extra functionality to it. Maybe you are trying to let it load some extra DLL files. Maybe you are writing the next obfuscator or deobfuscator. Or maybe you are trying to reroute some imported function to your own piece of code as a means of introspection.
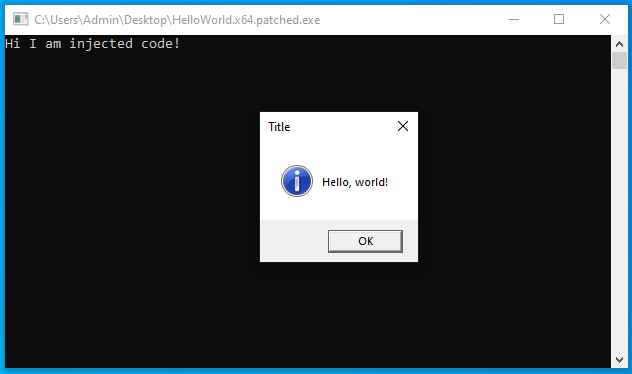 This is our end goal
This is our end goal
The problem is, you don’t have any source code available for the input binary. Maybe it is closed-source and you are reverse engineering it, or maybe you are writing a binary-level obfuscator instead of a source-level obfuscator.
In any case, you will be crafting some machine code that you will be inserting into one of the sections of the file.
This very likely will mean that you will need to use some functions defined in some external module.
Even a simple addition of a "Hi I am injected code!" print to the standard output requires a function call (e.g., puts).
A naive approach for adding code that calls such a function is to grab its address from the list of imported functions in the PE. But what if the function you need is not defined in this list? How do we go about adding new references to any external function, such that we can add any type of code to any type of PE file?
A Refresher on the Imports Directory
A call in a PE file
Let’s step back for a moment and have a refresher on how calls to external functions work in x86. Consider the following C snippet implementing the famous Hello World program:
1
2
3
4
int main()
{
MessageBoxA(0, "Hello, world!", "Title", MB_ICONINFORMATION);
}
A compiler may transform the call to something like the following 64-bit x86 code:
// ...
mov r9d, 0x40 // uType = MB_ICONINFORMATION
lea r8, qword [rip+4500] // lpCaption = &"Title"
lea rdx, qword [rip+4020] // lpText = &"Hello, world!"
xor ecx, ecx // hWnd = 0
call qword [0x140002008] // (*pMessageBoxA)();
// ...
The first four instructions make up the arguments. For our intents and purposes, the way these are emitted by the compiler is not really important information for us to understand how external function calls work.
The next instruction is the actual call instruction, and this is where the action happens.
You may notice that it is not a normal call.
Rather than directly referencing the MessageBoxA function with an immediate constant as its operand (i.e., call &MessageBoxA), the compiler actually reserved some space within our own PE file to store the address of MessageBoxA at (in our case this location is 0x140002008), and the call instruction reads a QWORD (a 64-bit integer) at this location and interprets that as the start address of the MessageBoxA function to jump to instead.
The reason the compiler takes this elaborate detour is that the address of our MessageBoxA function is not known yet at compile-time.
Since MessageBoxA is defined in some external module (user32.dll), and we don’t know where this module will be located in memory at run-time, the compiler cannot fill in the blanks.
Therefore, instead, it reserves some space within our own PE file for storing the address (think of it as a global variable), and asks Windows to put in the address of MessageBoxA upon loading our program.
And it does that, by using Import Lookup and Address Tables.
Import Lookup and Address Tables
So what do these tables look like?
The Import Lookup Tables (ILT) are stored in the Import Directory of the PE file, and contain lists of function names that should be resolved by Windows upon starting our PE file.
Every name is paired up with an entry in the Import Address Table (IAT), storing the actual addresses of the functions referenced in the ILT.
Similarly, code that wants to use the external functions defined in the lookup tables (such as our main function in our Hello World program) also references entries within the IAT.
In the PE file, this looks a bit like the following schematic:
 A typical Import Lookup Table (ILT) and corresponding Import Address Table (IAT) stored on the disk. The code stored in the
A typical Import Lookup Table (ILT) and corresponding Import Address Table (IAT) stored on the disk. The code stored in the .text section references entry 2 of the IAT, which corresponds to user32!MessageBoxA.
Note how both the name MessageBoxA and the call instruction both point to the same IAT entry 2.
To simplify things, assume that all entries within the IAT contain garbage data initially and are completely unusable (hence they are indicated with question marks).
However, at run-time, when Windows maps our PE into memory, each function defined in the lookup table will be resolved to an address, and the IAT will be populated accordingly:

 The same lookup and address tables at run time. The entries in the IAT are replaced with the resolved addresses of each function.
The same lookup and address tables at run time. The entries in the IAT are replaced with the resolved addresses of each function.
This way, when the program actually gets to reading the second IAT entry using the call instruction, it will read the resolved address of MessageBoxA located in the user32.dll module and transfer control to there.
To fully grasp the concept of how Windows populates the IAT, it may be a good exercise to make your own manual mapper and import address resolver. If this is something people are interested in, I may spent another blog post on how to do this.
Patching an Existing Import Table
OK, we know what these tables look like.
Why don’t we just find these tables in our input PE file, add an entry for puts, create some code that looks similar to our Hello World program, and call it the day?
Something like the following should do the trick, no?

 A suggestion for adding an entry to our lookup and address tables.
A suggestion for adding an entry to our lookup and address tables.
It so turns out editing PE files for which we do not have the source code is hard. Much harder than “simply” adding something to a table. First of all, PE files are full of addresses, offsets and sizes that need to be taken into account. Adding an entry will evidently increase the size of both of our lookup and address tables. If we are not careful with this and adjust our original PE file accordingly, we may be overwriting some bytes in the same data section that we should not be touching. This can have a variety of unpredictable consequences, ranging from the program executing normally, to it reading garbage data and throwing all kinds of access violation exceptions. Because without the source code available to us, who knows what the overridden data was originally used for:

 Extending the IAT may override other data in the PE file.
Extending the IAT may override other data in the PE file.
Ideally, we would want to keep the original data stored in the input PE intact. This means we have only two options. We could choose to either (A) make some space for the larger IAT by moving the data that follows down a bit, or (B) move the larger IAT to some other place in the PE file (such as another section):

 Two solutions for extending the IAT without overriding data.
Two solutions for extending the IAT without overriding data.
However, in both cases, this causes more problems.
Moving any type of data around in a PE file means all existing addresses within the original code that originally pointed to this data are no longer valid.
This means that all code needs to be updated, but this is far from a trivial task.
If we would have the original source code of the program, we would be able to just recompile everything.
However, since we do not, we would need to disassemble the .text section, find all references to any object within the original data section, calculate the new offsets accordingly, and reassemble the code with the newly obtained addresses.
Disassembly and reassembly is difficult on its own to do consistently right, especially with packed or obfuscated apps.
But even if we were able to do that, objects for which addresses are computed at run-time rather than at compile-time are virtually undetectable without some very sophisticated program analysis.
Both problems are very quickly to approach the halting problem, which is known to be unsolvable mathematically.
In other words, we need a more generic solution that always works regardless of what type of code is using our data sections, or what the original layout of the IAT was.
Jumping on Trampolines!
Since disassembly and reassmbly of the .text section is out of the question, we have to go for a variation of option B where we move the new ILT and IAT to a separate section.
It so turns out one solution that does work, is by using code trampolines.
Code trampolines are very small pieces of machine code whose only purpose is to jump to some other place in memory once it is executed. A trampoline in 64-bit x86 code may look something like the following:
mov rax, 0x140006008
jmp rax
The only thing it does is copy some destination address into the rax register, and then jump to it.
So how does this help us?
Trampolines allow us to do some rewiring of the imports without having to adjust any code at all in the .text section.
It is summarized in the following schematic:

 The final, generic solution using IAT trampolines.
The final, generic solution using IAT trampolines.
We start by getting rid of the original import lookup tables, but we keep the original address tables.
Note how the original code in the .text section still is referencing entries in this original IAT.
We then construct a new lookup and address table of our own and put it in a new PE section.
Since we control this new section, we are free to design these tables however we want without risking interfering with any of the other data stored in the PE file.
This means we can include our new puts entry as well.
Then, for every entry in the original IAT, we create a trampoline stub that uses the address of the corresponding entry in our new IAT. Finally, we patch the original IAT entries with hardcoded addresses to our created trampolines. This way, whenever a call is made for which an address is looked up in the original IAT, an address to one of our trampolines is used instead. This means that the call is then rerouted to the appropriate entry in our new IAT as dictated by the trampoline code, ensuring the right function is called in the end. This also means that we do not need to edit any of the original code sections either, all rewiring happens via the trampoline stubs:
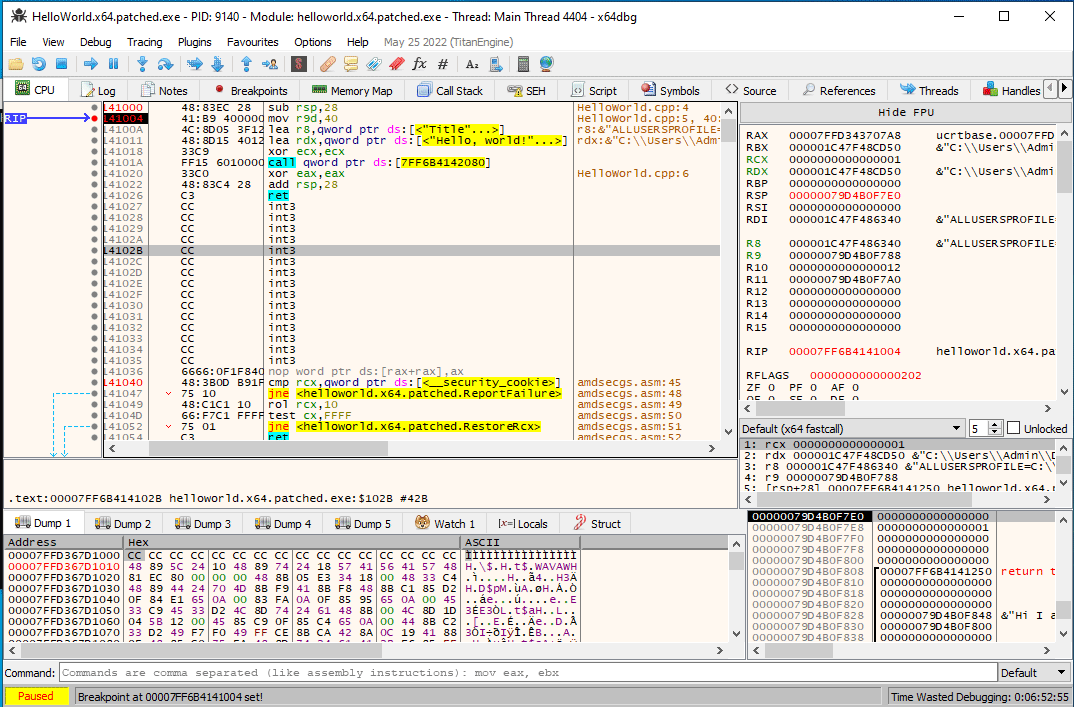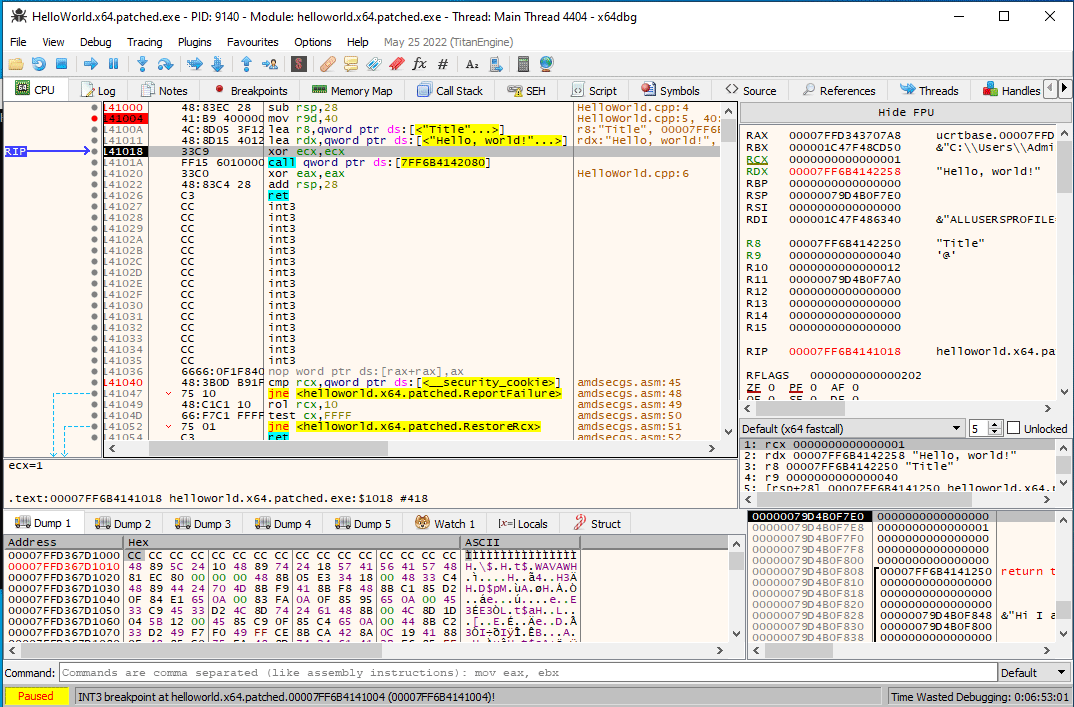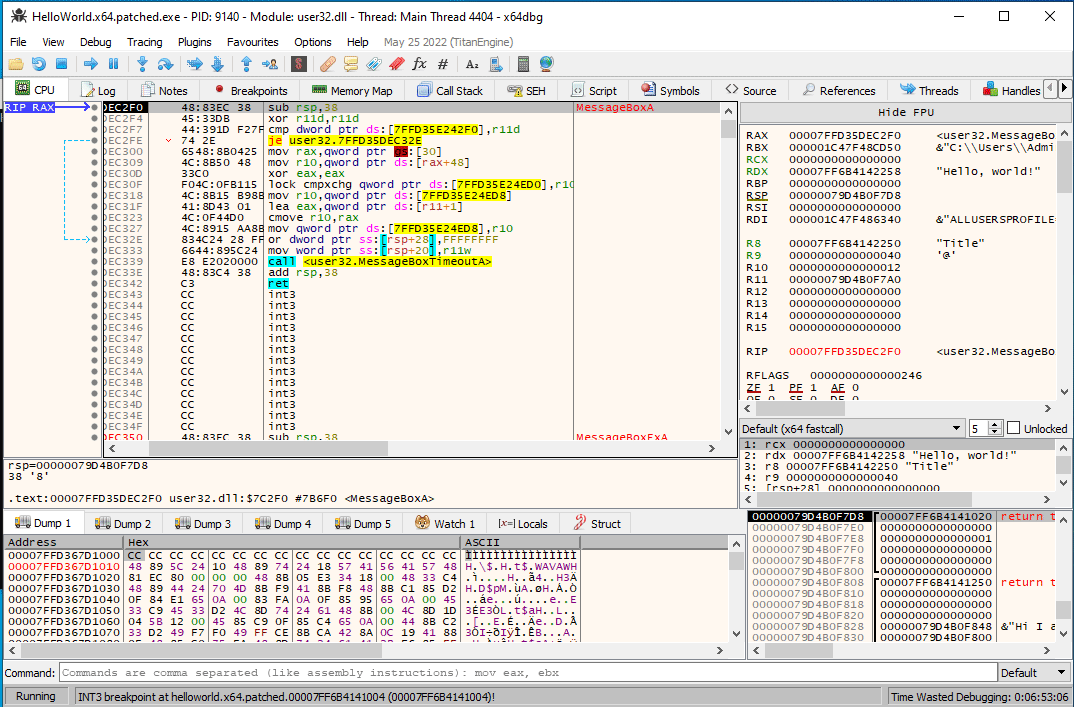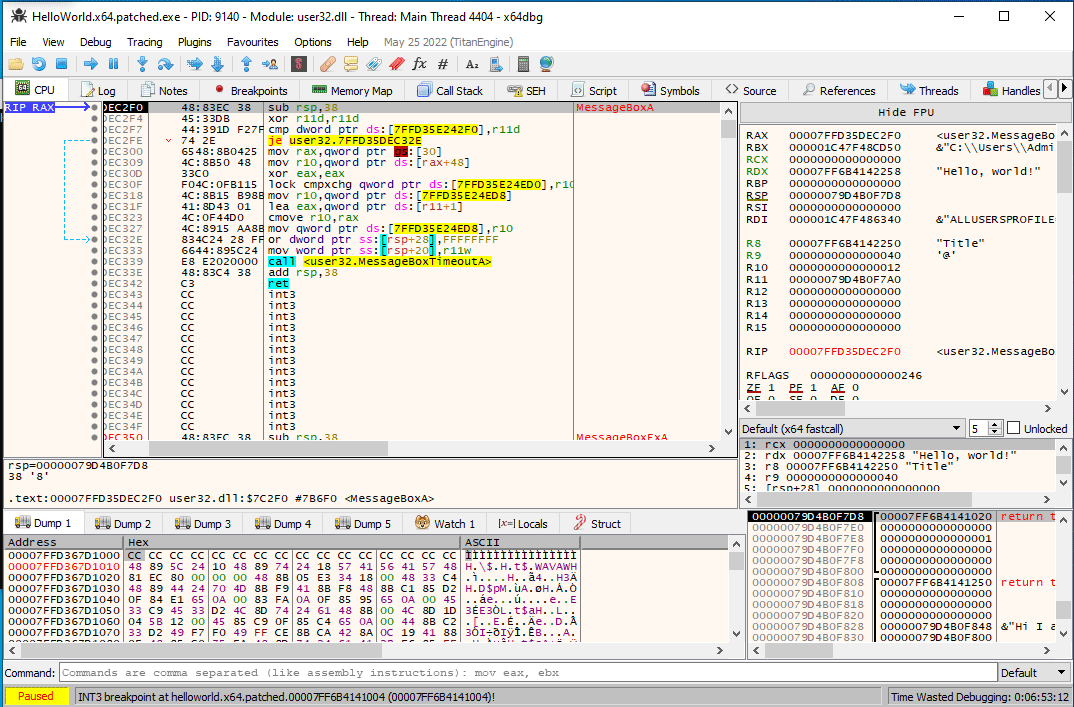 A call being trampolined to
A call being trampolined to MessageBoxA.
Of course, if we want to inject new code that uses any of the functions defined in our import tables, we do not need to use a trampoline. We can just reference directly into our new IAT:

 Directly referencing IAT entries in our new code is possible.
Directly referencing IAT entries in our new code is possible.
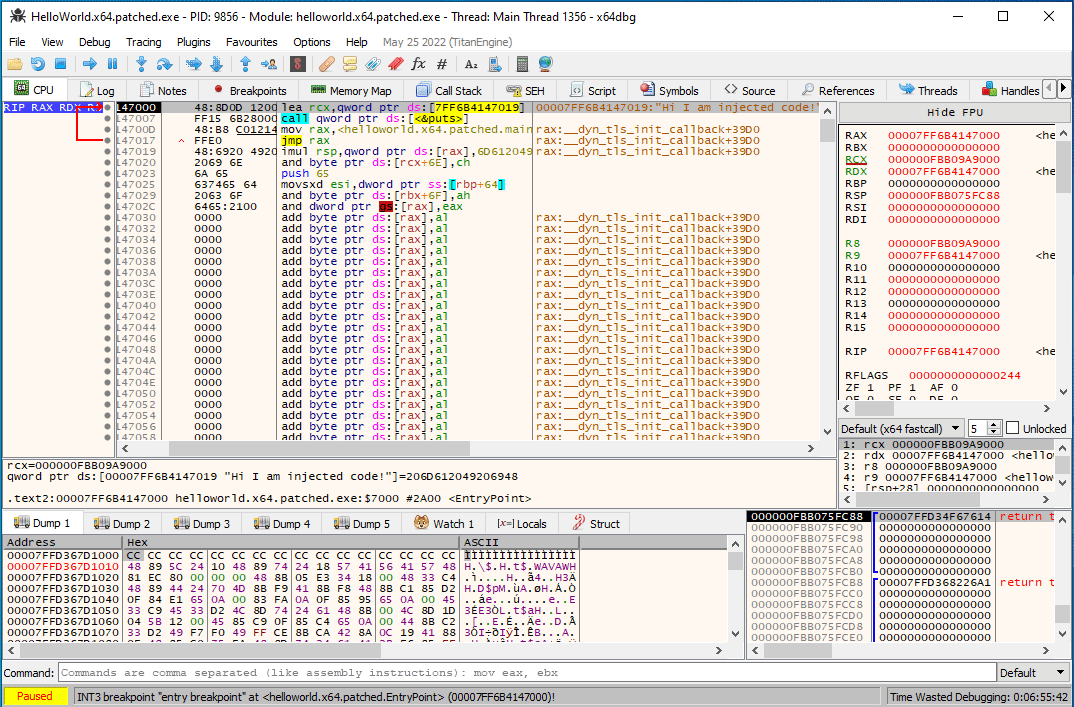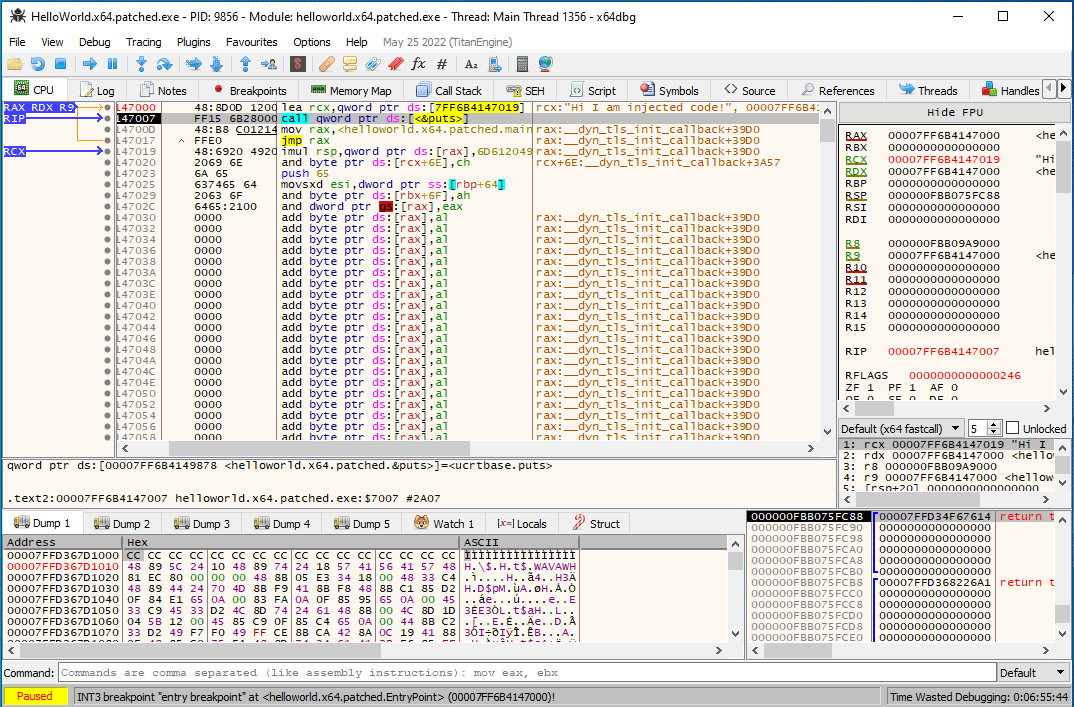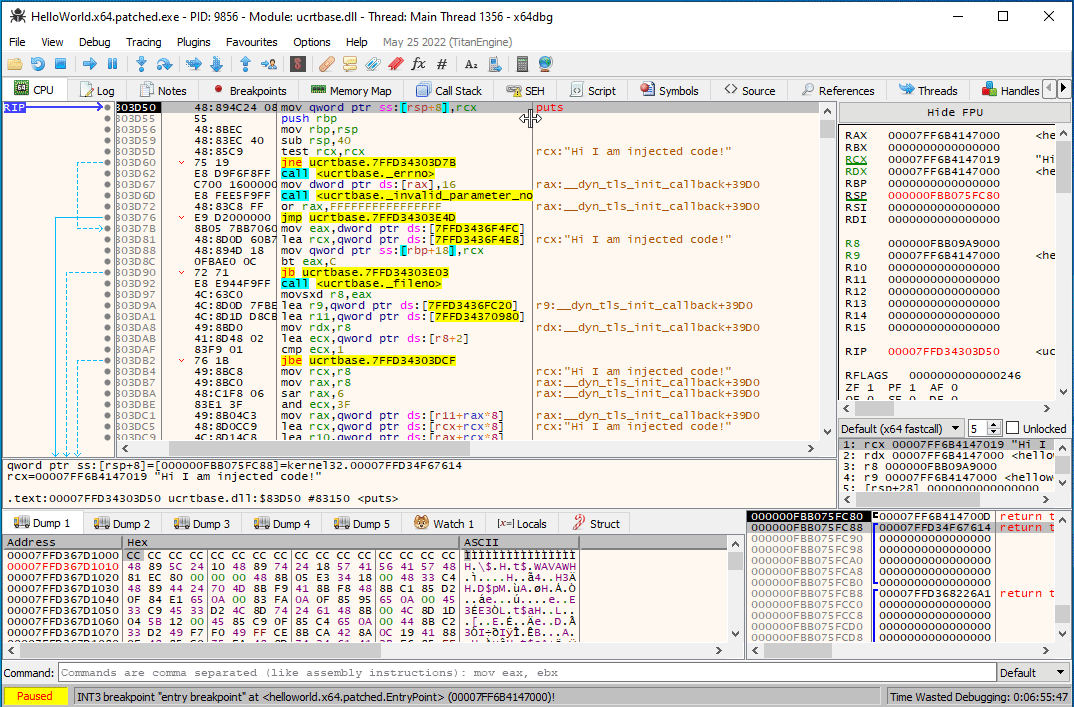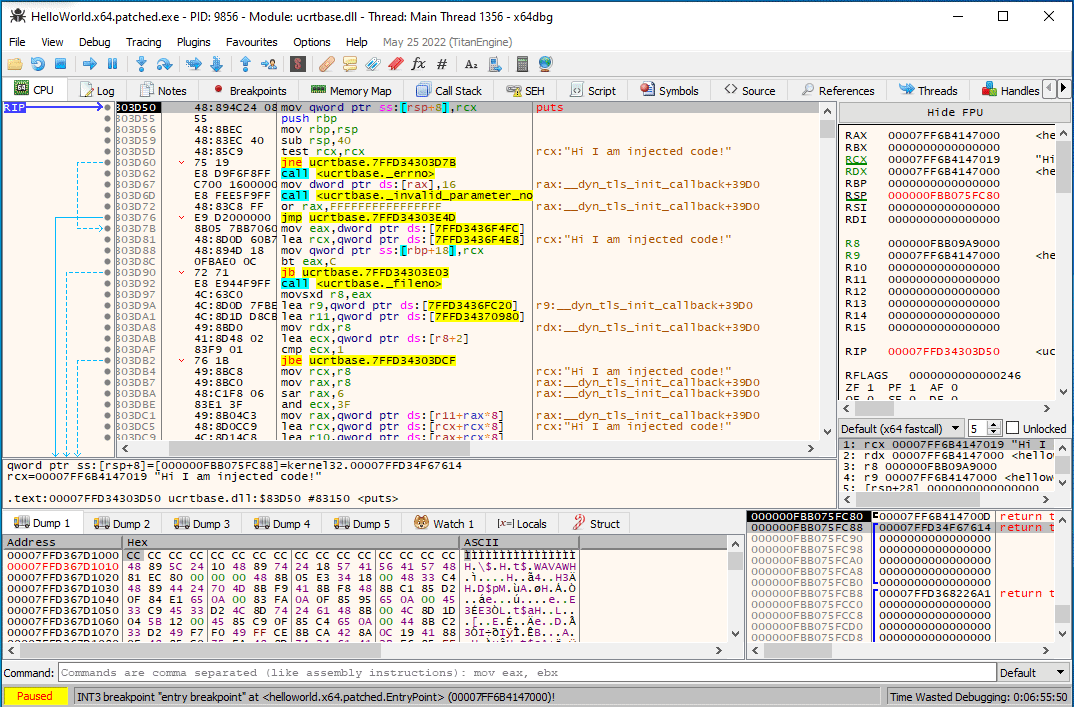 An injected call to
An injected call to puts that does not need a trampoline.
Implementation with AsmResolver
Now let’s try to automate this using C#. To implement everything, we need to do the following:
- Open the input PE file and read its headers and import directories.
- Inject a new section containing our new code.
- Rebuild the import directory and patch the original IAT with pointers to our new code trampolines.
- Write back the PE file.
As of writing this article, the latest version of AsmResolver (5.1.0) just started ticking all the requirements for this. How convenient!
It is almost as if this blog post is aligned with this latest release :^).
Injecting the New Code
First, the easy part.
We open our file as a PEFile and then turn it into a PEImage.
The former grants us access to raw sections, while the latter allows us to access higher-level structures such as the import directories easily.
1
2
var file = PEFile.FromFile(path);
var image = PEImage.FromFile(file);
Let’s import ucrtbase!puts into the PE image, and get the original entry point address of the executable file:
1
2
3
4
5
6
7
8
// Import ucrtbase.dll!puts into the PE image.
var ucrtbase = new ImportedModule("ucrtbase.dll");
var puts = new ImportedSymbol(0, "puts");
ucrtbase.Symbols.Add(puts);
image.Imports.Add(ucrtbase);
// Define an entry point symbol that we can reference later in our code.
var originalEntryPoint = new Symbol(file.GetReferenceToRva(file.OptionalHeader.AddressOfEntryPoint));
We can use these symbols to construct a new code segment that first prints "Hi I am injected code!" to the standard output, and then jumps to the original entry point of the input file:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
var code = new DataSegment(new byte[]
{
/* L0000: */ 0x48, 0x8D, 0x0D, 0x00, 0x00, 0x00, 0x00, // lea rcx, [rel message]
/* L0007: */ 0xFF, 0x15, 0x00, 0x00, 0x00, 0x00, // call [rel puts]
/* L000D: */ 0x48, 0xB8, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, // mov rax, &originalEntryPoint
/* L0017: */ 0xFF, 0xE0, // jmp rax
// message:
/* L0019: */ 0x48, 0x69, 0x20, 0x49, 0x20, 0x61, 0x6d, 0x20, 0x69, 0x6e, // "Hi I am in"
/* L0023: */ 0x6a, 0x65, 0x63, 0x74, 0x65, 0x64, 0x20, 0x63, 0x6f, 0x64, // "jected cod"
/* L002d: */ 0x65, 0x21, 0x00 // "e!."
}).AsPatchedSegment()
.Patch(0x3, AddressFixupType.Relative32BitAddress, 0x19 /* message */)
.Patch(0x9, AddressFixupType.Relative32BitAddress, puts)
.Patch(0xF, AddressFixupType.Absolute64BitAddress, originalEntryPoint);
We can then add it to a new section to our PE file:
1
2
3
4
file.Sections.Add(new PESection(
".text2",
SectionFlags.MemoryRead | SectionFlags.MemoryExecute | SectionFlags.ContentCode,
code));
Rebuilding the Import Tables
Now it is time to reconstruct the import directory. The core of the implementation can be found in the following loop. All there is to it is iterating over all imported symbols, constructing a new code trampoline for each of them, and patching out the original IAT entry with the address to our newly created trampoline stub:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
var platform = Platform.Get(file.FileHeader.Machine);
bool is64Bit = file.OptionalHeader.Magic == OptionalHeaderMagic.PE64;
var trampolineTable = new SegmentBuilder();
foreach (var module in image.Imports)
{
foreach (var originalSymbol in module.Symbols)
{
// Look up IAT RVA and get accompanying section.
if (originalSymbol.AddressTableEntry is null)
continue;
uint iatEntryRva = originalSymbol.AddressTableEntry!.Rva;
var section = file.GetSectionContainingRva(iatEntryRva);
if (section.Contents?.AsPatchedSegment() is not { } sectionContents)
continue;
// Construct trampoline stub.
var trampoline = platform.CreateThunkStub(originalSymbol);
var trampolineSymbol = new Symbol(trampoline.Segment.ToReference());
trampolineTable.Add(trampoline.Segment);
// Patch original IAT entry with address to the trampoline stub.
sectionContents.Patch(
iatEntryRva - sectionContents.Rva,
AddressFixupType.Absolute64BitAddress,
trampolineSymbol);
// Update section contents.
section.Contents = sectionContents;
}
}
In the code above, we use a SegmentBuilder to concatenate all trampoline stubs together into one segment.
This allows us to add them easily as one new section to the PE file.
Since the trampolines themselves are essentially just thunk stubs, they can be constructed using the Platform::CreateThunkStub method.
This is an abstraction built into AsmResolver that allows for constructing thunks for a specific architecture, making our code platform-agnostic.
Finally, we add our new code trampolines and import directories and address tables as new sections to our PE file:
1
2
3
4
file.Sections.Add(new PESection(
".trmpln",
SectionFlags.ContentCode | SectionFlags.MemoryRead | SectionFlags.MemoryExecute,
trampolineTable));
1
2
3
4
5
6
7
8
9
10
11
12
var importBuffer = new ImportDirectoryBuffer(image.MachineType != MachineType.Amd64);
foreach (var module in image.Imports)
importBuffer.AddModule(module);
file.Sections.Add(new PESection(
".idata2",
SectionFlags.ContentCode | SectionFlags.ContentUninitializedData | SectionFlags.MemoryRead,
new SegmentBuilder
{
{importBuffer, 8},
{importBuffer.ImportAddressDirectory, 8},
}));
Saving the Binary
The only thing that is left is instructing AsmResolver to recompute all offsets and sizes, and update the data directories accordingly in the headers of the PE such that our new import tables are being used instead:
1
2
3
4
5
6
7
8
9
10
file.UpdateHeaders(); // Recomputes all offsets.
var dataDirectories = file.OptionalHeader.DataDirectories;
dataDirectories[(int) DataDirectoryIndex.ImportDirectory] = new(
importBuffer.Rva,
importBuffer.GetVirtualSize());
dataDirectories[(int) DataDirectoryIndex.IatDirectory] = new(
importBuffer.ImportAddressDirectory.Rva,
importBuffer.ImportAddressDirectory.GetVirtualSize());
Writing the file back to the disk is then as simple as the following:
1
file.Write("output.exe");
If you did everything right, you end up with something like the following:
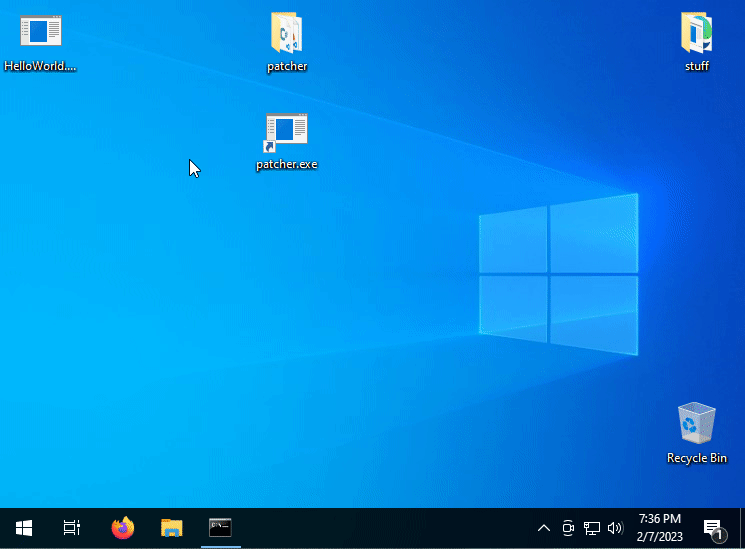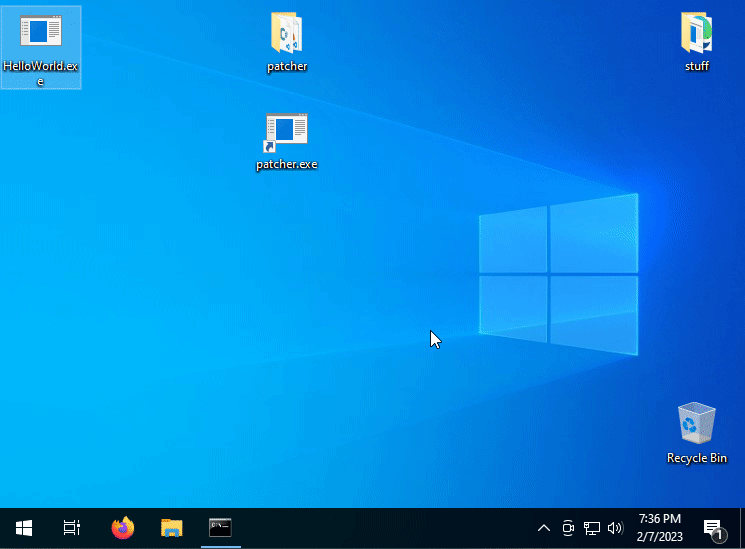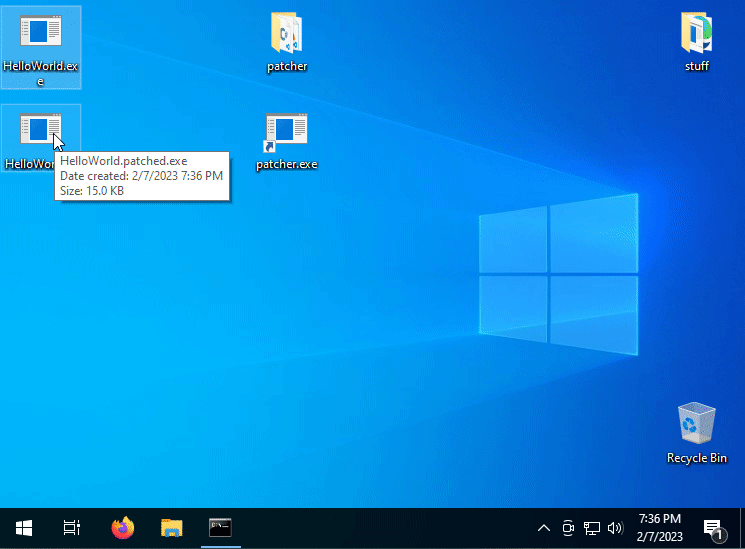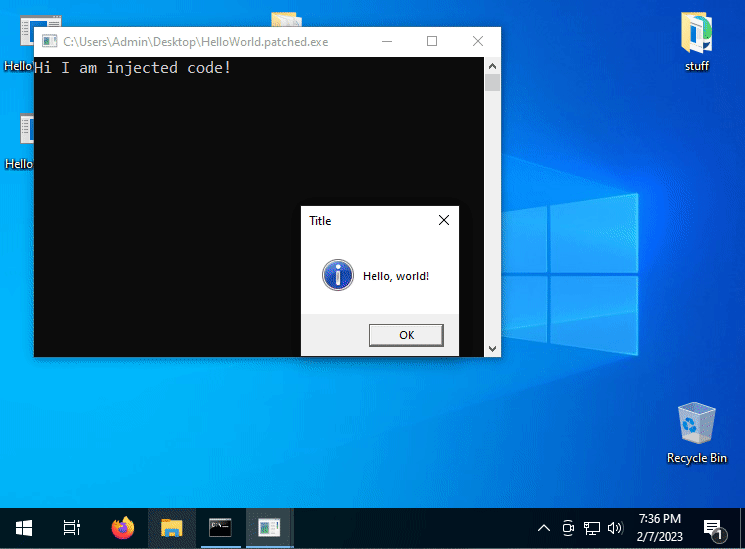 It works!
It works!
Full Source Code
For brevity, I left a few bits and pieces of the implementation out from this post (e.g., regarding base relocations). The full source can be found on my GitHub:
Final Words
Byte-patching a PE file is easy, but when a patch requires resizing fundamental data structures, things get complicated really fast. In this post, we have seen how we can circumvent this problem in the case of rebuilding import directories. Using code trampolines, we were able to arbitrarily modify an import directory, and include the functions we need without overriding any of the data segments and thus changing the semantics of the input PE file.
This approach works well, but it has a couple of downsides. First, it requires new sections to be created and trampolines to be injected, which can increase the size of the file significantly. Second, the old import lookup table is not quite removed from the original PE file, it is just not referenced anymore. Repeat this process of patching with trampolines a few times in sequence, and your file will be cluttered with a lot of unreferenced data segments and trampoline chains. Nonetheless, since this solution only does very minimal assumptions on the structure of the code of the executable, it should work pretty much for any PE file, making this solution nice and generic.
There is a chance that this trampoline generation will be fully integrated into AsmResolver’s PE builders directly, but it will probably undergo a few more iterations before it gets fully accepted into the main API. Stay tuned if you are interested in that!
Happy hacking!